Infrastructure
Overview
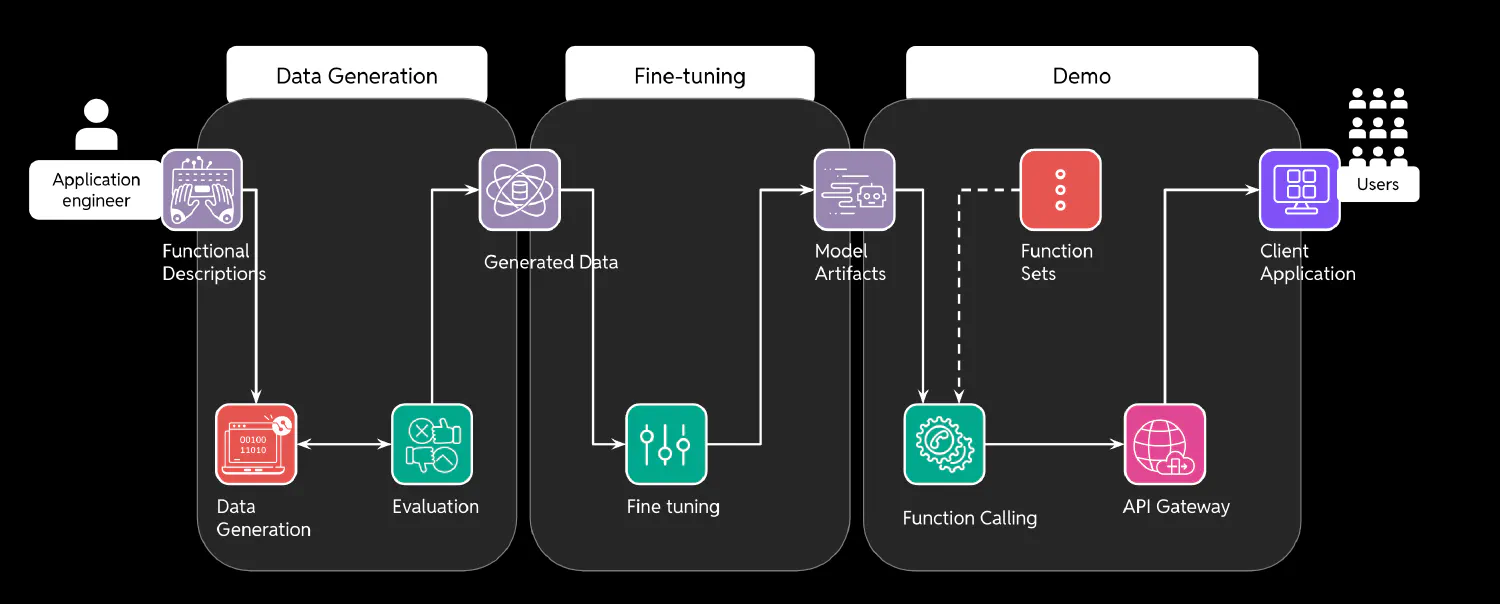
SynthCall integrates data generation with function calling, addressing limitations and challenges from which current large language models suffer. The infrastructure comprises three main modular components: data generation, data evaluation, and model fine-tuning (with SageMaker).
Data Generation
The data generation pipeline has four key steps: function creation, model execution, response structuring, and prompt iteration.
-
Function Creation and Documentation: Function descriptions are provided by an application engineer and include clear docstrings and typing hints. These descriptions serve as the foundation of the pipeline and act as prompts to help guide the generation process.
-
On-Premises Model Running: Since safeguarding customer data is a priority, Ollama is utilized for running the models as it is an on-premises solution. This approach avoids sending any potentially sensitive information to external servers, maintaining a high level of data privacy and control.
SynthCall employes the Llama 3.1 8b instruct model for data generation, striking a balance between performance and resource efficiency. However, since SynthCall was created with modularity in mind, customers can use larger local or cloud models for the generation step should they so choose.
-
Structured Output Generation: The next step in SynthCall’s generation pipeline leverages LangChain with ChatOllama for structured output. This setup allows SynthCall to generate a consistent & standardized JSON format, regardless of variations in model responses. By setting precise expectations for the format, synthetic data is ensured to be structured and actionable, which is essential for downstream use in both data evaluation and model fine-tuning.
-
Iterative Prompt Refinement: The generation process involves iterating on system prompts to meet set expectations. SynthCall begins by generating a small set of data from the initial prompts and function descriptions. From there, the small dataset is assessed to determine if any further prompt engineering needs to take place.
Data Evaluation
After the data generation phase, an automated evaluation process is implemented to ensure only high-quality data is being generated. During this phase, SynthCall:
- Incorporates automated quality metrics to reduce human involvement;
- Quantifies data relevance and filters out low-quality generation pairs; and
- Improves efficiency and reliability of data for fine-tuning.
In order to achieve the above, the SynthCall evaluation pipeline utilizes reverse query generation, which is powered by the AWS Bedrock service. The pipeline involves the following:
- Generating pairs to provide query and argument information
- Executing functions in the backend to validate argument compatibility
- Producing natural language responses based on function call results
- Creating new potential queries that the response could answer
- Assessing mean cosine similarity between original and generated queries
- Implementing similarity scores as thresholds to filter low-quality pairs
Fine-Tuning
Once the synthetic data is generated and evaluated, the final step involves fine-tuning a model. The process begins by loading the generated training data directly from scalable storage. From there, the training environment is configured to fine-tune the model using the synthetic data. The fine-tuning process adjusts the model’s parameters to improve its performance and accuracy for the customer’s given functions. After training is complete, the resulting model artifacts are saved back to storage for future use.